OpenELM
November 25, 2022
Crossposted from CarperAI Blog
CarperAI is releasing OpenELM, an open-source library combining large language models with evolutionary algorithms for code synthesis!
ELM stands for Evolution Through Large Models, a technique from a recent OpenAI paper demonstrating that large language models can act as intelligent mutation operators in an evolutionary algorithm, enabling diverse and high quality generation of code in domains not seen in the language model’s training set.
The initial release of OpenELM, version 0.0.1, includes:
-
An implementation of the basic ELM setup, including MAP-Elites for generated code, either from a diff model or from prompt engineering an existing language model.
-
The Sodarace 2D environment, along with several other baseline environments.
-
A sandbox using gVisor with a Docker container and Flask to safely run code generated by language models.
-
Benchmarking of mutation LLMs using a toy environment.
In addition, we are also releasing an open-source diff model fine-tuned on GitHub diffs from Salesforce’ CodeGen 350M code synthesis model, under an MIT license. A diff model is an autoregressive language model trained on edits to a piece of code, formatted in Unified Diff Format. These diff models can suggest, given a section of code and a description of the desired change (like a commit message), an intelligent change to the code that fits the description, marking the lines added, changed, and deleted in diff format. This diff model will let you more easily generate intelligent code suggestions in ELM.
If you are interested in joining the OpenELM project, check out our Discord or Twitter.
Find out more about how it works below!
Evolutionary algorithms and open-endedness
Evolutionary algorithms (EAs) are a type of population based optimization algorithm inspired by biological evolution. These algorithms start with a population of potential solutions to a problem (often called “individuals”), and then apply evolutionary operators such as mutation, crossover, and selection to the population, in order to generate new populations of solutions.
Over time, the average quality of the solutions in the population will increase, as the “fittest” individuals are more likely to be selected for reproduction, and their offspring will inherit their “fitness”. Evolutionary algorithms therefore rely on a pre-defined fitness function which evaluates the performance or quality of an individual in the population.
This search technique is gradient free and makes very few assumptions about the structure of the fitness landscape, making evolutionary algorithms a powerful optimizer for domains where fitness can be efficiently evaluated and the evolutionary operators can explore the search space effectively.
One fundamental open problem in the evolutionary algorithms community is that of open-endedness. This field seeks to create algorithmic systems that produce never-ending innovation—just as biological evolution is capable of seemingly endless creativity and complexity. Of course, true endless innovation seems out of reach for AI for the foreseeable future, but creating open-ended artifacts of greater and greater complexity has the potential to unlock powerful new generative algorithms. Crucially, open-endedness requires the ability to search outside of the distribution of previous experience, which is typically difficult for deep learning models to do. A recent paper from OpenAI called Evolution Through Large Models (ELM) enables a step in this direction and explores the links between evolutionary algorithms and large language models (LLMs).
ELM = evolutionary algorithms + LLMs
In a nutshell, ELM is a way to combine evolutionary algorithms and large language models for generation of diverse data.
Evolutionary algorithms provide a way to generate diverse and novel data by making mutations and changes to candidates in the domain of interest, such as code. Language models provide a way to encode human knowledge to guide these mutations intelligently. Combining these two techniques therefore allows the search procedure to say on the “manifold of functionality” and lets the language model drive the evolutionary algorithm towards areas of the solution space that neither technique could find on their own.
To set the scene a little bit, there have been numerous papers in the past year or two using large language models (LLMs) for code generation and synthesis, including OpenAIs Codex and DeepMind’s AlphaCode. Several of these papers, such AlphaCode, have focused on ways to generate code for specific domains including programming puzzles and solutions. However, sometimes the domain we want to generate code for has limited data that is only rarely found or not found in the training distribution. In this case, attempting to generate high quality code with prompt engineering will usually be impractical.
ELM demonstrates that by incentivising diversity in program generation, we can create code in domains not in the training dataset using only a single seed program.
How ELM works
ELM consists of three primary components: a mutation operator in the form of an LLM, an evolutionary algorithm that uses the LLM to create a diverse space of candidate solutions, and a way to fine-tune the LLM using its previously generated data.
The first component consists of a diff model—a model trained on git diffs to suggest, given a section of code and a commit message, a diff describing a modification to the code. This model allows us to start with a single seed program and output a variety of diverse alternative programs in the same domain, for use in the evolutionary algorithm.
For the second component, we use the MAP-Elites evolutionary algorithm. It is a so-called quality-diversity algorithm, which works via generating a grid of niches called a behavior space spanning the space of possible solutions. When each candidate solution is generated, we evaluate its fitness and compare it against the current candidate in the corresponding grid cell—if it is better than it is placed into the grid cell. Over time, this map fills up with both high performing and diverse solutions.
The third and final component is to fine-tune the language model to improve its performance further. Because candidate solutions from the diff model are in the form of a diff, we can fine-tune our model using the data in the MAP-Elites grid, which we have already selected to have high fitness and diversity. In addition, we can also further fine-tune our model using reinforcement learning to invent solutions conditionally depending on some property of the environment.
Taken together, ELM shows a path forward for a creative loop of generating arbitrary open-ended data with a language model in domains not seen in the training set, followed by fine-tuning this language model on the generated data to further enhance its capabilities.
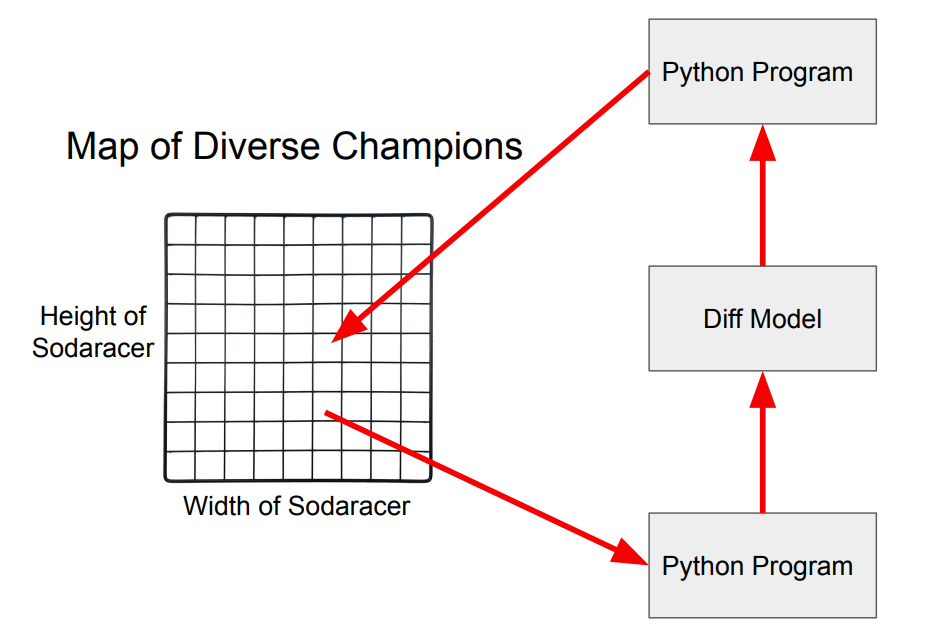
What makes a good ELM environment?
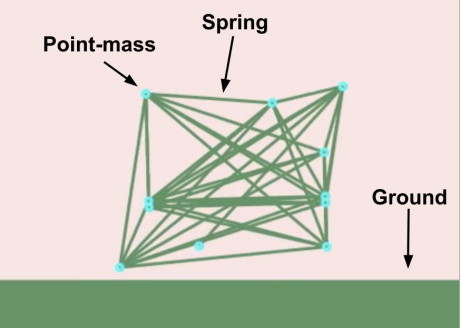
An example Sodaracer robot, consisting of masses and springs (muscles) connecting them. The objective in this domain is to design a robot which effectively travels across the terrain.
The ELM paper and the OpenELM library implement several different baseline environments to play with. The primary domain used in the paper is the Sodarace environment—a 2D physics-based simulation of robots moving across a variety of terrains. These robots are fully specified by a dictionary determining their joints, muscles, and size, but this dictionary is itself generated by the Python programs generated by the diff model. In this way, we can use ELM to generate diverse and high performing robots in the Sodarace environment, bootstrapped from a single seed program.
We also implement a toy environment for image generation, in which ELM is tasked with generating programs which in turn create images matching a test image. Good domains to apply ELM have a high potential for open-ended and arbitrary complexity in generated artifacts, and the ability to evaluate fitness or performance relatively easily. For example, we might apply ELM to generation of programs with particular properties, such as solutions to programming puzzles, or to code which can generate design specifications.
By releasing this open-source package for ELM we hope to encourage more research into the use of large language models with evolutionary algorithms, which has the potential to enable a new type of more sample-efficient evolutionary computing. By bringing together the evolutionary algorithm community and the language model community we can allow for the potential of both to be fully realised.