The Lottery Ticket Hypothesis
January 30, 2020
The Lottery Ticket Hypothesis is an interesting 2019 paper by Jonathan Frankle and Michael Carbin at MIT that attempts to explain the generalisation capability of deep neural networks, and identify situations where a smaller network can be trained to a similar accuracy as a large network. I recently presented this paper for a class and decided to post an extended version of my presentation here.
Motivation
Deep neural networks are usually highly over-parameterized, containing numerous redundant connections. In other words, in most neural networks the number of parameters is significantly larger than the amount of training data. Empirically, over-parameterization improves optimization speed and generalisation, despite the fact that traditional learning theory says over-parameterization is a recipe for overfitting. However, there have been several attempts to train a network, then keep the “important” connections in the network while stripping away the rest, to improve the computational cost of inference. This technique is called pruning. Typically, a pruning algorithm consists of applying some heuristic to identify redundancies in the weights of a large pre-trained model, such as removing the connections with the smallest weights. The pruned network is then fine-tuned to learn better weights for the remaining connections and compensate for accuracy loss from removing connections.
Recent studies have shown that the connections in a DNN can be pruned by as much as 90% without reducing test accuracy. However, naively attempting to re-initialize and train a pruned network from scratch gives worse performance than training a larger network and then pruning it. This paper attempts to answer the question of why this happens and propose techniques for identifying situations in which a pruned network will have high accuracy.
The Hypothesis
The authors propose the Lottery Ticket Hypothesis:
A randomly-initialized, dense neural network contains a subnetwork that is initialized such that - when trained in isolation - it can match or exceed the test accuracy of the original network after training for at most the same number of iterations.
To break this down: the subnetwork is a binary mask applied to the initial random parameters. When trained alone with its initialized parameters, this subnetwork can reach an accuracy at least as high as the original network in the same or fewer training iterations. This subnetwork is the winning “lottery ticket” - in this analogy, training a large network is like buying many lottery tickets, which gives a higher chance of “winning”: getting a high accuracy on the task. Almost all possible subnetworks are losing tickets, however the larger the network, the higher the chances that a winning ticket exists.
The paper shows that subnetworks can be found by training a network, removing \(p%\) of the smallest magnitude parameters by fixing their value at 0, then resetting the remaining parameters to their initial values, creating the winning ticket. This is called one-shot pruning - the authors also found that iterative pruning, in which this process is repeated and \(p^\frac{1}{n}\) parameters are pruned over n rounds, creates smaller and equally accurate winning tickets than one-shot pruning.
Experiments and Results
The authors used this procedure to identify winning tickets with fully connected networks on the MNIST dataset, and with convolutional networks on the CIFAR10 image classification dataset. The pruned networks can be as small as 3.6% of the size of the original (usually 10-20%), but achieve at least as good accuracy in the same training time. In some cases, the winning ticket networks reach higher test accuracy than the original in a shorter training time.
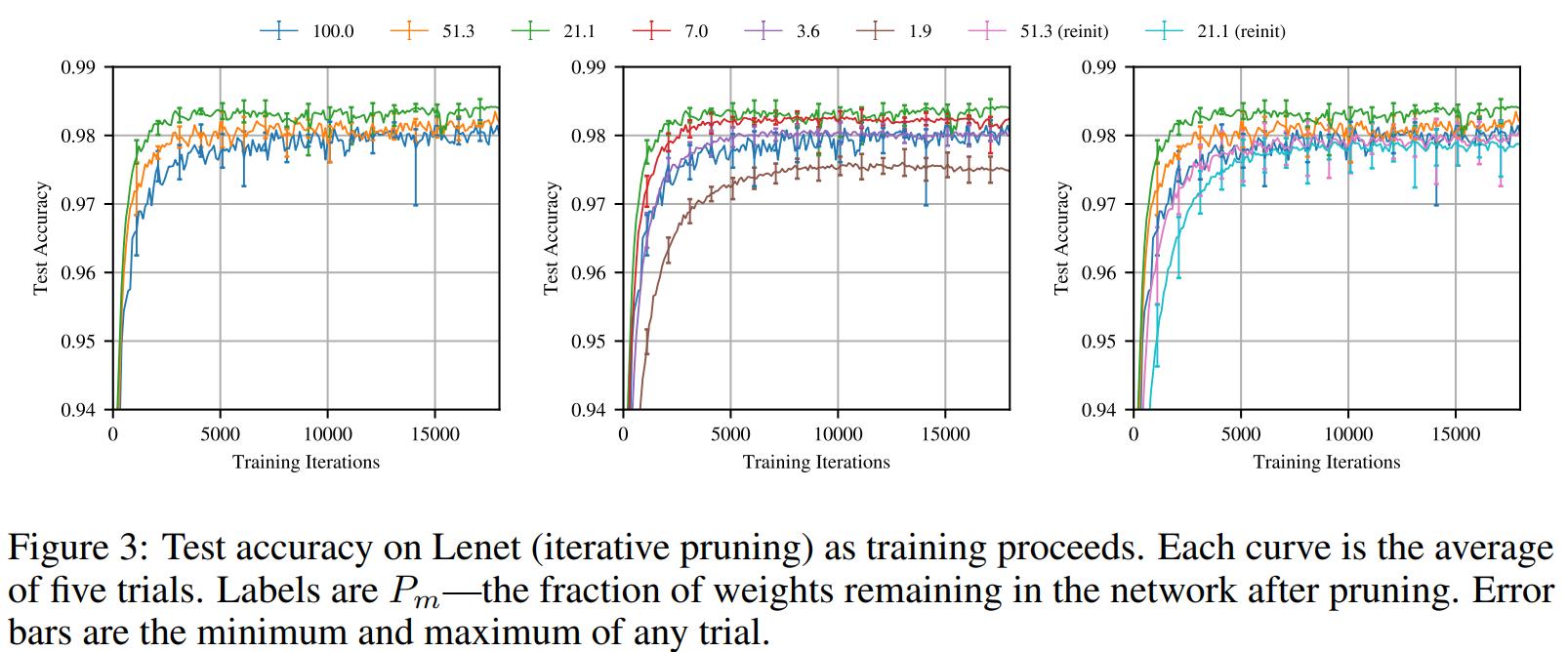
Crucially, when the winning tickets are randomly reinitialized rather than being trained with their original weights, their performance is far worse than the original network. This indicates that the pruned network architecture by itself does not ensure a subnetwork will be a winning ticket - the initialization AND the architecture form the sucessful subnetwork.
The paper also shows that the reason winning tickets are successful is not because their initializations are close to their final values after training, as might be suspected, since the weights of winning tickets change more during training than other parameters. The authors suspect winning tickets may simply be initialized in an area of the loss landscape that is particularly conducive for optimization.
A Final Conjecture
The authors then arrive at a conjecture (that they do not attempt to prove): SGD seeks out and trains a subset of well-initialized weights. As a result, larger networks are easier to train from scratch, because there are more possible subnetworks that might be winning tickets.